Important Links
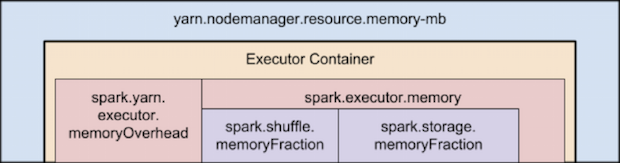
Parameters need tuning based on instance type
- --conf spark.dynamicAllocation.enabled = true | false
- --conf spark.executor.instances = 2 || --num-executors 2
- --conf spark.executor.memory = 2g || --executor-memory 2g
- --conf spark.executor.cores = 2 || --executor-cores 2
spark.yarn.executor.memoryOverhead=max(384, .10 * spark.executor.memory)
Control Parallelism
- --conf spark.default.parallelism = 200
- --conf spark.sql.shuffle.partitions = 200
- Minimum Partitions
/**
* Default min number of partitions for Hadoop RDDs when not given by user
* Notice that we use math.min so the "defaultMinPartitions" cannot be higher than 2.
* The reasons for this are discussed in https://github.com/mesos/spark/pull/718
*/
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
How much memory each tasks would have?
- --conf spark.memory.fraction = 0.6
- --conf spark.memory.storageFraction = 0.5
Task Memory = (spark.executor.memory * spark.memory.fraction * spark.memory.storageFraction) / spark.executor.cores
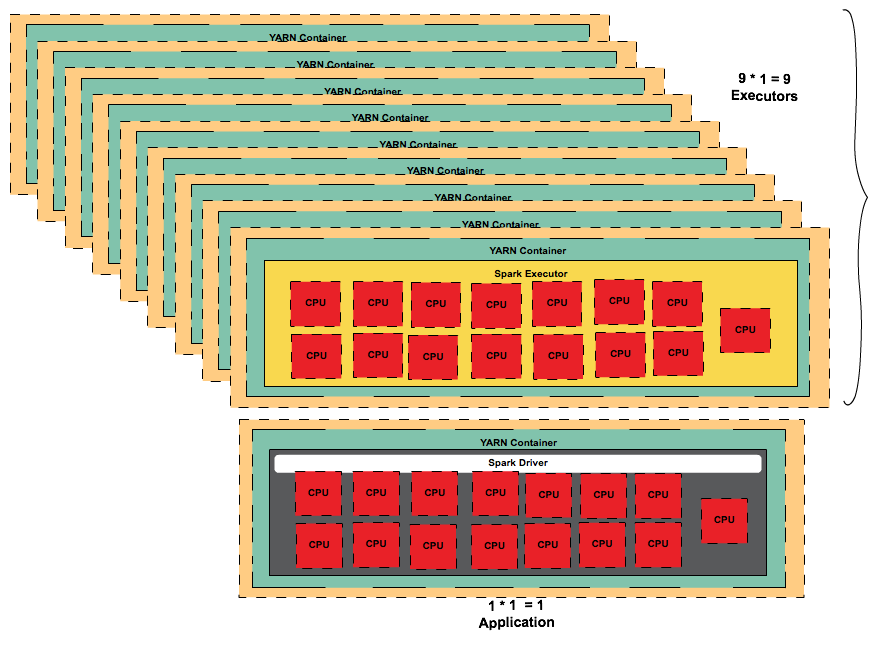
Tiny executors [One Executor per core]
| Change Number of Nodes | Reserved for OS/Hadoop/YARN | Calculated Values | |||
|---|---|---|---|---|---|
| m4.4xlarge | Nodes | 10 | |||
| CPU Cores | 16 | 15 | |||
| RAM | 64 GB | 63 | |||
| --executor-cores | 1 | ||||
| executor-per-node | 15 | ||||
| --num-executors | 149 | ||||
| executor-memory with overhead | 4 | ||||
| --executor-memory | 3 |

Fat executors [One Executor per node]
| Change Number of Nodes | Reserved for OS/Hadoop/YARN | Calculated Values | |||
|---|---|---|---|---|---|
| m4.4xlarge | Nodes | 10 | |||
| CPU Cores | 16 | 15 | |||
| RAM | 64 GB | 63 | |||
| --executor-cores | 15 | ||||
| executor-per-node | 1 | ||||
| --num-executors | 9 | ||||
| executor-memory with overhead | 63 | ||||
| --executor-memory | 56 |
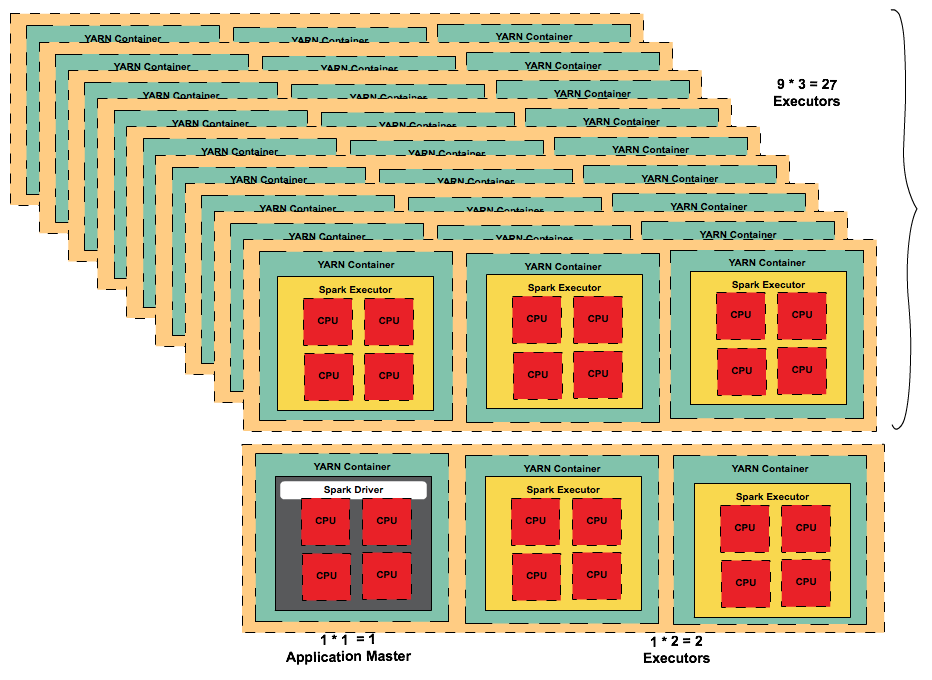
Balanced Fat and Tiny
| Change Number of Nodes | Reserved for OS/Hadoop/YARN | Calculated Values | |||
|---|---|---|---|---|---|
| m4.4xlarge | Nodes | 10 | |||
| CPU Cores | 16 | 15 | |||
| RAM | 64 GB | 63 | |||
| --executor-cores | 4 | ||||
| executor-per-node | 3 | ||||
| --num-executors | 29 | ||||
| executor-memory with overhead | 21 | ||||
| --executor-memory | 18 |
Happy Coding!!!
package org.apache.hadoop.mapred;
/*Import Statements*/
public abstract class FileInputFormat <K , V> implements InputFormat <K , V> {
....
protected long computeSplitSize(long goalSize,
long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
...
}
How does Hadoop & Spark Control Partitioning ?
To Be Continued...